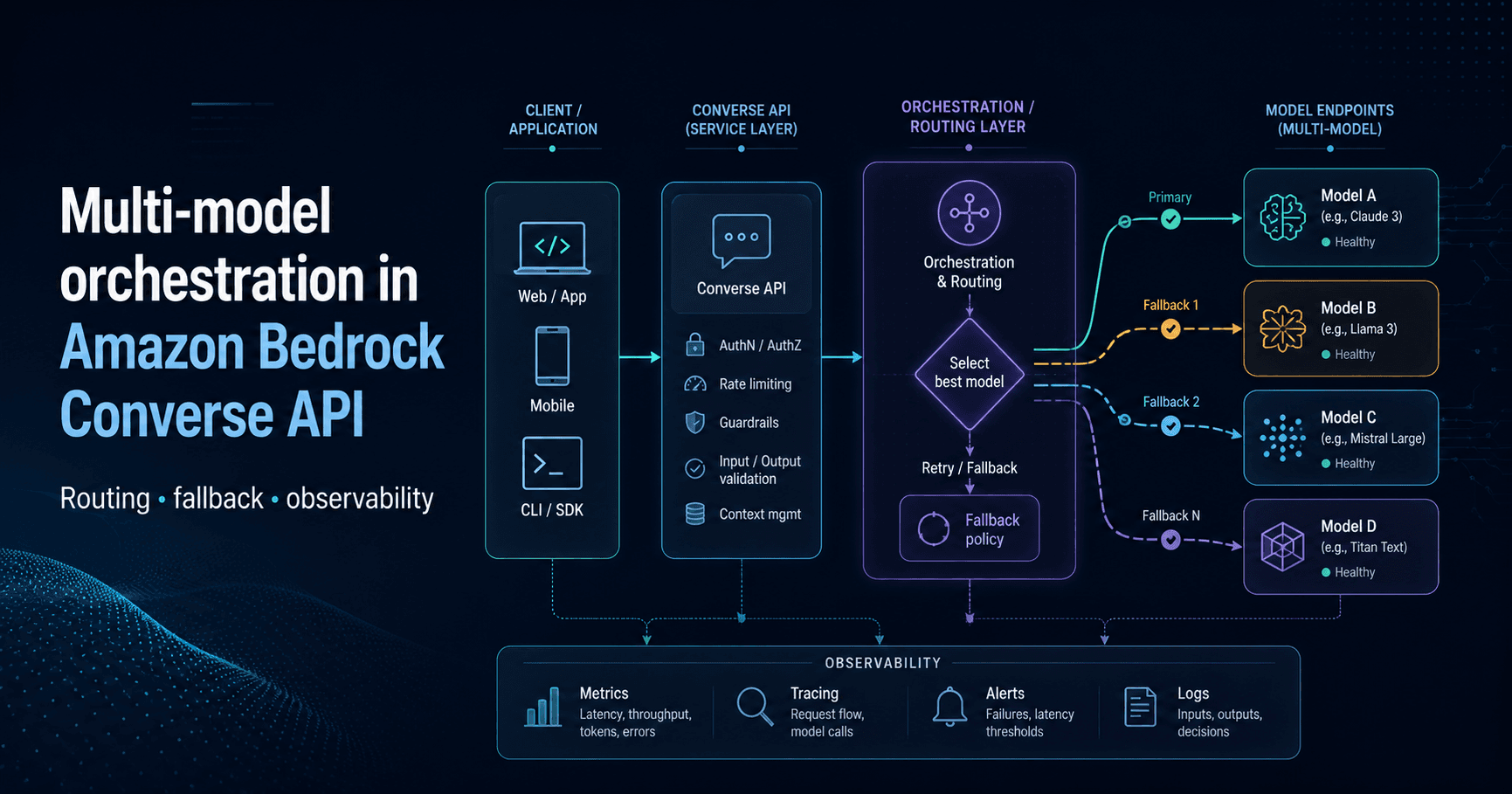
Multi-model orchestration in Amazon Bedrock Converse API
The AI industry has a continuous pipeline of models in various stages of development and release. As one frontier model gains adoption, another is already approaching launch with new capabilities, different tradeoffs, and fresh evaluation benchmarks.
This creates a challenge for enterprise teams. The problem is not deciding whether a new model is better than the last one. The problem is building applications so tightly coupled to today's model that adopting tomorrow's requires a rewrite.
Organizations that realize the most value from AI will not necessarily be the ones that pick the right model first. They will be the ones that build reusable architectures that can accommodate changes in models, requirements, and business priorities without repeated redesign efforts.
The Amazon Bedrock Converse API addresses this directly. Rather than building application logic around a single model, developers can use a consistent interface across multiple foundation models, allowing routing, observability, and governance patterns to remain stable as models change.
In this post, I will use Claude Opus 4.8 as the implementation example to demonstrate how to build a multi-model architecture on AWS that reduces lock-in, simplifies model evaluation, supports intelligent model routing, and turns future model upgrades into a configuration change instead of an engineering project.
Why multi-model architecture matters on AWS
Most teams do not realize they are creating model lock-in until it becomes expensive.
The first implementation works. The proof of concept succeeds. Then a new model appears with better reasoning, lower latency, or a more attractive pricing structure. Suddenly application code, prompt formatting, SDK integrations, and evaluation tooling all need updates.
The most common challenges include:
- Model coupling through provider-specific APIs
- Evaluation lock-in that prevents meaningful A/B testing
- Operational risk when a model is deprecated or unavailable
- Fragmented observability across providers
- Difficulty controlling cost and latency across workloads
The solution is not continuously switching models. The solution is introducing a routing and abstraction layer early.
This is the same architectural principle that drove API gateways, container orchestration, and cloud-native platforms. Decouple the implementation from the interface.
What the Bedrock Converse API solves
The Amazon Bedrock Converse API provides a standardized interface for interacting with multiple foundation models through a single request format.
Instead of writing separate integrations for Claude, Llama, Mistral, and future models, developers can use a common API structure that standardizes:
- Request payloads
- Conversation history
- Inference configuration
- Tool use patterns
- Response structures
One implementation pattern for a multi-model architecture on AWS looks like this:
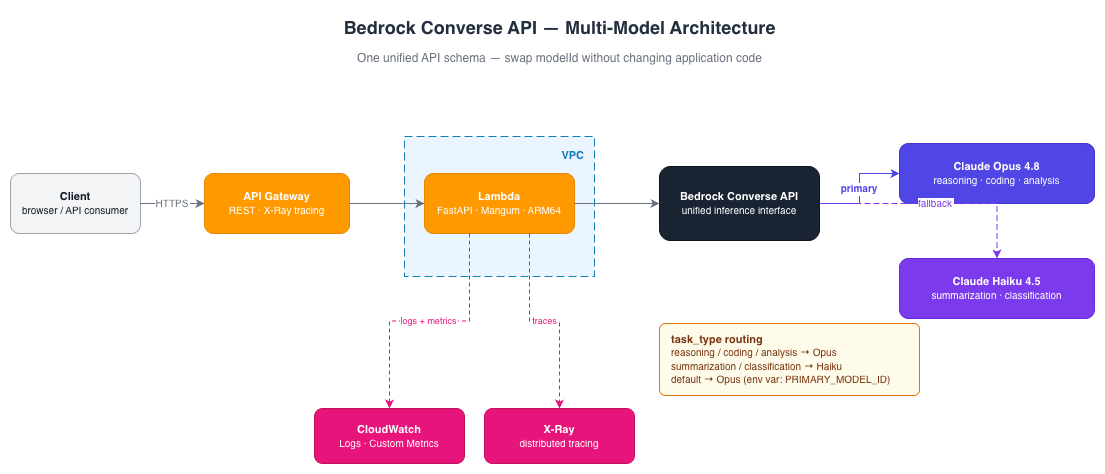
The important architectural benefit is simple: your application code does not change when your model selection changes. The only thing that changes is the model identifier.
Why Claude Opus 4.8 is a strong primary model
For complex reasoning workloads, Claude Opus 4.8 is a strong primary model within a multi-model architecture.
Its strengths include:
- Long-context document analysis
- Multi-step agent workflows
- Large codebase navigation
- Complex research and synthesis tasks
- Consistent output quality in production environments
This makes it a natural fit for workloads such as:
- Earnings call analysis
- Regulatory document review
- Threat intelligence investigations
- Literature reviews in life sciences
- Enterprise knowledge management systems
The value comes from the architecture: you can evaluate and replace the model without redesigning the surrounding platform.
Amazon Bedrock Converse API examples
Full runnable code:
blog/examples/examples.pyProduction client:backend/src/bedrock_client.py
Single-turn inference
A basic Converse API request remains consistent regardless of the underlying model. The response shape is identical whether the request is handled by Claude, Llama, or any other Bedrock-hosted model.
import boto3
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
response = bedrock.converse(
modelId="us.anthropic.claude-opus-4-8",
messages=[
{
"role": "user",
"content": [{"text": "What are the key tradeoffs between synchronous and async Lambda invocation?"}],
}
],
inferenceConfig={"maxTokens": 1024},
)
print(response["output"]["message"]["content"][0]["text"])
print(f"Tokens — in: {response['usage']['inputTokens']}, out: {response['usage']['outputTokens']}")
Multi-turn conversations
Conversation history is represented as a simple message array. Append turns and pass the full array on each call. The same pattern works for any Bedrock model — the modelId is the only thing that changes.
conversation = [
{"role": "user", "content": [{"text": "I'm designing a RAG pipeline on AWS. Where should I start?"}]},
{"role": "assistant", "content": [{"text": "Start with your retrieval strategy. Are you using structured or unstructured data?"}]},
{"role": "user", "content": [{"text": "Unstructured — PDFs and internal wikis."}]},
]
response = bedrock.converse(
modelId="us.anthropic.claude-opus-4-8",
messages=conversation,
system=[{"text": "You are an AWS solutions architect. Be concise and opinionated."}],
inferenceConfig={"maxTokens": 2048, "temperature": 0.5},
)
print(response["output"]["message"]["content"][0]["text"])
Model routing in Amazon Bedrock
One of the most valuable patterns is model routing. Instead of exposing model identifiers to application teams, requests are classified by workload type: reasoning, coding, analysis, summarization, or classification. The routing layer determines which model processes the request, allowing platform teams to balance quality, latency, and cost without changing application code.
def route_model(task_type: str) -> str:
routing = {
"reasoning": "us.anthropic.claude-opus-4-8",
"coding": "us.anthropic.claude-opus-4-8",
"analysis": "us.anthropic.claude-opus-4-8",
"summarization": "us.anthropic.claude-haiku-4-5-20251001",
"classification": "us.anthropic.claude-haiku-4-5-20251001",
}
return routing.get(task_type, "us.anthropic.claude-opus-4-8")
tasks = [
("Design a multi-region failover strategy for DynamoDB Global Tables.", "reasoning"),
("Summarize this paragraph in one sentence: AWS Lambda is a serverless compute...", "summarization"),
]
for text, task_type in tasks:
model_id = route_model(task_type)
response = bedrock.converse(
modelId=model_id,
messages=[{"role": "user", "content": [{"text": text}]}],
inferenceConfig={"maxTokens": 512},
)
print(f"[{task_type} -> {model_id}]")
print(response["output"]["message"]["content"][0]["text"])
In the production client, this routing table is driven by environment variables — swapping model tiers is a configuration change, not a code change:
# backend/src/bedrock_client.py
MODEL_PRIMARY = settings.primary_model_id # PRIMARY_MODEL_ID env var
MODEL_FALLBACK = settings.fallback_model_id # FALLBACK_MODEL_ID env var
ROUTING_TABLE: dict[str, str] = {
"reasoning": MODEL_PRIMARY,
"coding": MODEL_PRIMARY,
"analysis": MODEL_PRIMARY,
"summarization": MODEL_FALLBACK,
"classification": MODEL_FALLBACK,
"default": MODEL_PRIMARY,
}
Fallback patterns
Production systems need resiliency. When a primary model experiences throttling, timeout issues, or availability problems, the platform can automatically retry against a secondary model. From the caller's perspective, nothing changes.
def converse_with_fallback(text: str, primary: str, fallback: str) -> dict:
for model_id in [primary, fallback]:
try:
response = bedrock.converse(
modelId=model_id,
messages=[{"role": "user", "content": [{"text": text}]}],
inferenceConfig={"maxTokens": 1024},
)
return {
"model_id": model_id,
"content": response["output"]["message"]["content"][0]["text"],
"fallback_used": model_id == fallback,
}
except Exception as e:
if model_id == fallback:
raise
print(f"Primary model failed ({e}), trying fallback...")
raise RuntimeError("All models failed")
result = converse_with_fallback(
text="Explain cross-region replication latency tradeoffs.",
primary="us.anthropic.claude-opus-4-8",
fallback="us.anthropic.claude-haiku-4-5-20251001",
)
print(f"Served by: {result['model_id']} (fallback={result['fallback_used']})")
The production BedrockConverseClient in bedrock_client.py handles this automatically — it catches ClientError and TimeoutError from the primary model and retries against MODEL_FALLBACK without any changes to the caller.
Operational benefits for enterprise teams
Multi-model architecture creates advantages beyond flexibility.
Faster evaluation cycles — New models can be introduced behind feature flags and compared against existing workloads without redeploying applications.
Cost optimization — Expensive reasoning tasks can use premium models while simpler workloads use lower-cost alternatives.
Improved resiliency — Fallback routing reduces dependence on a single model provider or deployment.
Centralized governance — Content filtering, audit logging, observability, and PII controls can be implemented once and applied consistently.
Better observability — A unified routing layer creates a single place to measure latency, token consumption, error rates, user feedback, and model utilization across every request.
Observability considerations
If you are building AI applications with Amazon Bedrock, observability should be part of the architecture from day one.
Track:
- First-token latency and end-to-end response time
- Input and output token counts (returned in every Converse response)
- Model selection distribution — which
modelIdhandled what percentage of traffic - Error rates: throttling, timeouts, content filter hits
- Human evaluation scores and downstream task success rates
Services such as CloudWatch, AWS X-Ray, and a lightweight evaluation harness run against a golden set on each model upgrade provide the visibility needed to make informed routing decisions over time.
Conclusion
The core principle behind multi-model architecture is not which model you choose today — it is how easily you can change that decision tomorrow.
By standardizing interactions through the Amazon Bedrock Converse API, you decouple application logic from model implementations, simplify evaluation, improve resiliency, and create a platform that can evolve alongside the steady flow of new models.
Claude Opus 4.8 is an excellent example of a frontier model that benefits from this approach. But the architecture itself is the real investment. Model routing, fallback handling, governance, and observability continue to provide value regardless of which model ultimately processes the request.
If you are building AI applications with Amazon Bedrock, start with a simple abstraction layer, implement model routing, and establish baseline evaluation metrics. Future model upgrades should become configuration changes — not engineering projects.
For deeper guidance, explore the Amazon Bedrock documentation, the Converse API reference, and the Claude Opus 4.8 announcement. The full demo repository is available on GitHub.
The future is not about finding the perfect model. It is about building systems that can take advantage of whatever comes next.