TL;DR
Vector search is great at finding semantically similar content, but it struggles with broad keyword-heavy queries common in regulatory and clinical document search. By combining BM25 keyword matching with k-NN vector search and fusing results with Reciprocal Rank Fusion (RRF), we improved retrieval quality, particularly for recall-heavy queries common in compliance and safety workflows.
The Problem Nobody Warns You About
If you've built a RAG (Retrieval-Augmented Generation) system, you've probably followed the standard playbook: chunk your documents, embed them with a model like Titan or OpenAI, store the vectors, and retrieve the top-K most similar chunks at query time.
This works beautifully for specific questions:
"What are the contraindications for apixaban?"
The embedding model understands the semantic intent. It finds chunks that discuss apixaban contraindications even if the exact word "contraindications" doesn't appear. Vector search shines here.
But try this query:
"Which drugs have bleeding warnings?"
Suddenly, vector search struggles. Why? Because this query needs to match across many documents, finding every drug that mentions "bleeding" in a warnings context. The embedding for this query lands in a vague region of the vector space — it's semantically close to lots of things about bleeding, warnings, drugs, and adverse events, but not specifically close to any one document's bleeding warning section.
The result: you get back 3-4 chunks from one or two drugs, miss several others entirely, and the generated answer is incomplete.
This isn't a theoretical problem. In regulatory document search — FDA drug labels, clinical protocols, safety reports — the most important queries are often broad: "List all drugs with boxed warnings", "Which protocols require liver function monitoring?", "What drugs interact with anticoagulants?". These are exactly the queries where vector-only search falls short.
Why Vector Search Fails on Broad Queries
To understand the failure, think about what an embedding model actually does. It compresses a chunk of text into a fixed-size vector (say, 1024 dimensions) that captures the overall semantic meaning. Two chunks about apixaban dosing will have similar vectors. A chunk about warfarin bleeding warnings and a chunk about apixaban bleeding warnings will have somewhat similar vectors — but they'll also be similar to chunks about bleeding in general, surgical bleeding, GI bleeding from NSAIDs, and so on.
When you search for "Which drugs have bleeding warnings?", the k-NN search returns the chunks whose vectors are closest to the query vector. But "closest" in a 1024-dimensional space doesn't mean "contains the keywords 'bleeding' and 'warnings' in a drug label context." It means "semantically similar to the general concept of drugs and bleeding warnings." The distinction matters.
BM25 (the classic keyword search algorithm) doesn't have this problem. It looks for the actual terms "bleeding" and "warnings" in the text, scores documents by term frequency and inverse document frequency, and ranks and surfaces documents containing those terms, typically providing strong recall for keyword-driven queries. It's not smart about paraphrasing, but it's thorough.
The insight: Vector search is semantically precise for focused queries but can under-retrieve on recall-heavy, cross-document queries.
The Solution: Hybrid Search with RRF Fusion
Hybrid search runs both retrieval methods in parallel and merges the results. The architecture looks like this:
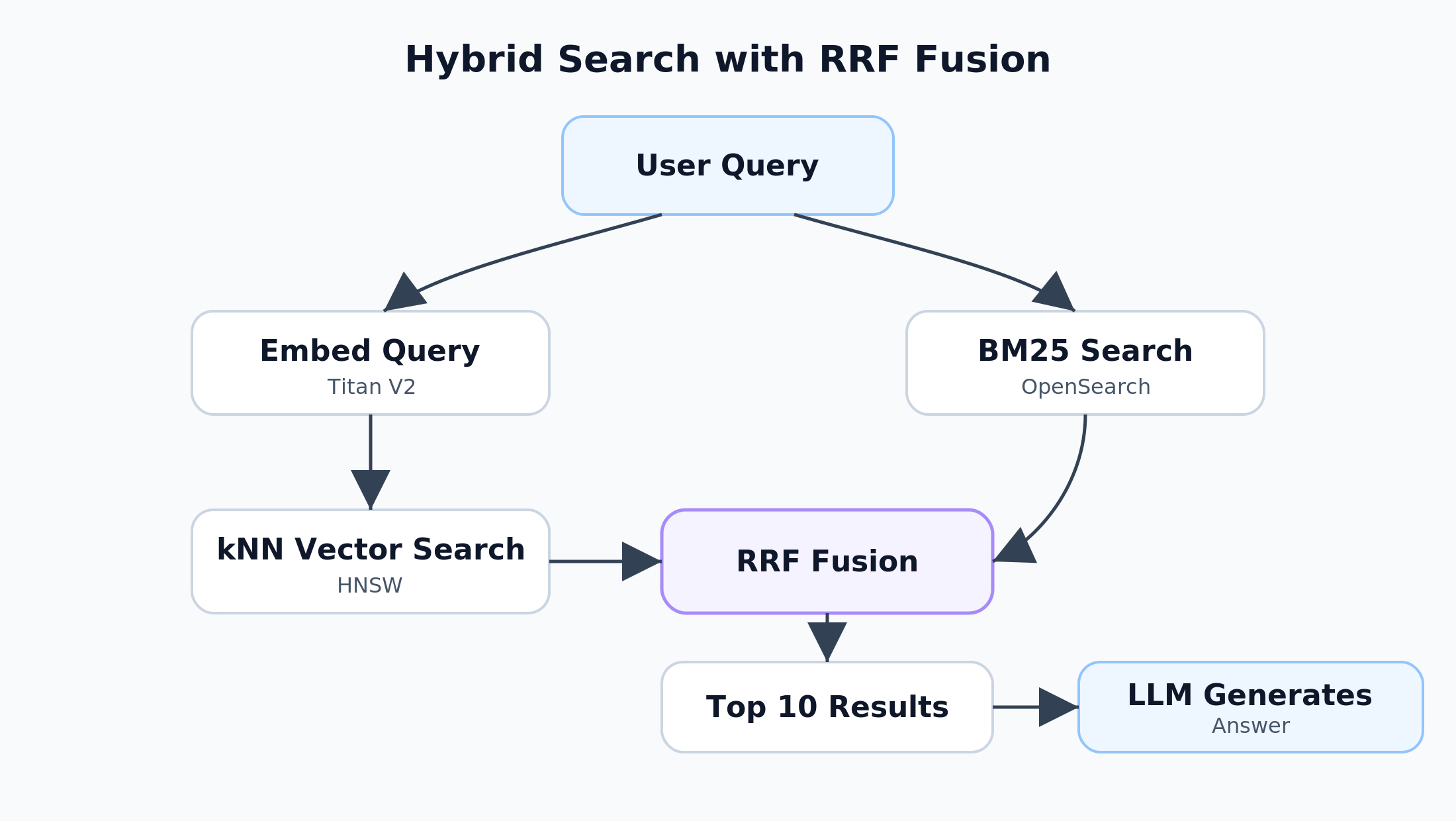
The key is the fusion step. Reciprocal Rank Fusion (RRF) is elegantly simple:
score(doc) = \sum \frac{1}{k + rank_i(doc)}
def rrf_fusion(result_lists, k=60):
scores = {}
for results in result_lists:
for rank, doc_id in enumerate(results):
scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank + 1)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
For each result list, a document's contribution to its final score is 1 / (k + rank + 1), where k is a constant (typically 60) and rank is its position in that list. A document ranked #1 in BM25 and #3 in k-NN gets a higher fused score than a document ranked #1 in k-NN alone.
RRF has a useful property: it avoids the need for score normalization across retrieval methods. BM25 scores and k-NN distances are on completely different scales, but RRF only uses rank positions, so they combine cleanly.
Real Results
Here's what the same queries return with hybrid search enabled, against a corpus of 142 FDA drug labels (~10,800 chunks):
| Query Type |
Vector Only |
Hybrid Search |
| Broad recall queries |
Misses entities |
High coverage across documents |
| Cross-document queries |
Partial results |
More complete retrieval |
| Specific semantic queries |
Strong |
Strong (slight boost from BM25) |
Broad query (BM25 strength):
"Which drugs have bleeding warnings?"
Hybrid search found Naproxen (NSAID with GI bleeding boxed warning) and Apixaban (anticoagulant with bleeding warnings and spinal hematoma boxed warning), with detailed citations from multiple label sections. Vector-only search returned only apixaban.
Cross-drug query (hybrid strength):
"Which drugs have black box warnings about suicidal thoughts?"
Hybrid search found Pregabalin, Gabapentin (antiepileptic drug warnings), Duloxetine (antidepressant warning), and Quetiapine (antipsychotic warning) — four different drug classes, each with the specific suicidality boxed warning language. Vector-only search returned only two of these.
Specific query (k-NN strength):
"What is the recommended dosage for apixaban in atrial fibrillation?"
Both approaches work well here, but hybrid search still benefits from BM25 boosting chunks that contain the exact terms "dosage", "apixaban", and "atrial fibrillation."
Choosing Your Embedding Dimensions
Amazon Titan Text Embeddings V2 offers three output dimensions: 256, 512, and 1024. This is a decision you make once — changing dimensions later means re-embedding and re-indexing your entire corpus.
Representative results from public benchmarks and AWS sample evaluations show:
| Dimension |
MTEB Retrieval (NDCG@10) |
Retention vs 1024 |
Storage per vector |
| 1024 |
0.51 |
100% (baseline) |
4 KB |
| 512 |
~0.505 |
99.0% |
2 KB |
| 256 |
~0.494 |
96.8% |
1 KB |
Sources: MTEB Retrieval benchmarks; AWS Titan V2 sample notebooks; AWS Machine Learning Blog on Titan embeddings and OpenSearch. Exact performance varies by dataset and query distribution.
For most use cases, 512 is the sweet spot — you lose only 1% retrieval accuracy and halve your storage. But for regulatory and clinical document search, I'd argue for 1024. Here's why:
The 3.2% accuracy gap between 256 and 1024 sounds small, but in a compliance context — where missing a relevant safety finding matters — even small retrieval quality differences add up across a large corpus.
The storage argument for lower dimensions also doesn't hold at typical regulatory corpus sizes. 100,000 vectors at 1024 dimensions is ~400 MB. That's nothing for an OpenSearch cluster. You'd need millions of vectors before the storage difference between 512 and 1024 becomes meaningful.
One more thing: Titan V2 at 1024 dimensions actually outperforms Titan V1 at 1536 dimensions on retrieval benchmarks (0.51 vs 0.47 NDCG@10) (source). More dimensions isn't always better — the V2 training improvements matter more than the extra 512 dimensions.
The Chunking Problem Nobody Talks About
There's a second retrieval quality issue that's independent of vector vs. keyword search: chunk boundaries.
Most RAG tutorials show you how to split text into fixed-size windows (500 words, 1000 tokens, etc.) with some overlap. This works fine for blog posts and Wikipedia articles. It performs poorly for structured documents.
A 200-page clinical protocol has sections like Inclusion Criteria, Exclusion Criteria, Primary Endpoints, Adverse Events. With fixed 512-word chunking, a chunk boundary can land right in the middle of the Exclusion Criteria section:
Chunk 47: [...tail end of Inclusion Criteria...]
[...first half of Exclusion Criteria...]
Chunk 48: [...second half of Exclusion Criteria...]
[...start of Dosing Schedule...]
When someone asks "What are the exclusion criteria?", Chunk 47 is a partial match polluted with inclusion criteria text. The embedding blends both concepts. BM25 matches "criteria" in both the inclusion and exclusion parts. The answer is confused.
Section-aware chunking solves this by detecting section boundaries (numbered headings, font changes, structural markers) and chunking at those boundaries instead of at fixed word counts. Each chunk is a complete section or sub-section, with metadata recording its position in the document hierarchy:
{
"text": "Patients are excluded if they have any of the following...",
"sectionPath": ["6. Study Population", "6.2 Exclusion Criteria"]
}
This gives you:
Cleaner embeddings — each vector represents one coherent concept, not a blend of two adjacent sections
Better BM25 matching — section headers like "Exclusion Criteria" are in the same chunk as the criteria themselves
Filtered search — you can restrict queries to specific section types ("search only in Adverse Events sections")
Recent work on hybrid and multi-stage retrieval systems shows consistent gains in top-K retrieval quality compared to single-method approaches (e.g., DIRSRT, 2026). In practice, sentence-boundary chunking often matches more complex semantic chunking approaches at lower computational cost for many workloads. It's one of the highest-impact optimizations you can make after implementing hybrid search — though the gap between strategies is typically single-digit percentage points, not transformative on its own.
Architecture at a Glance
The full system runs on AWS with minimal operational overhead:
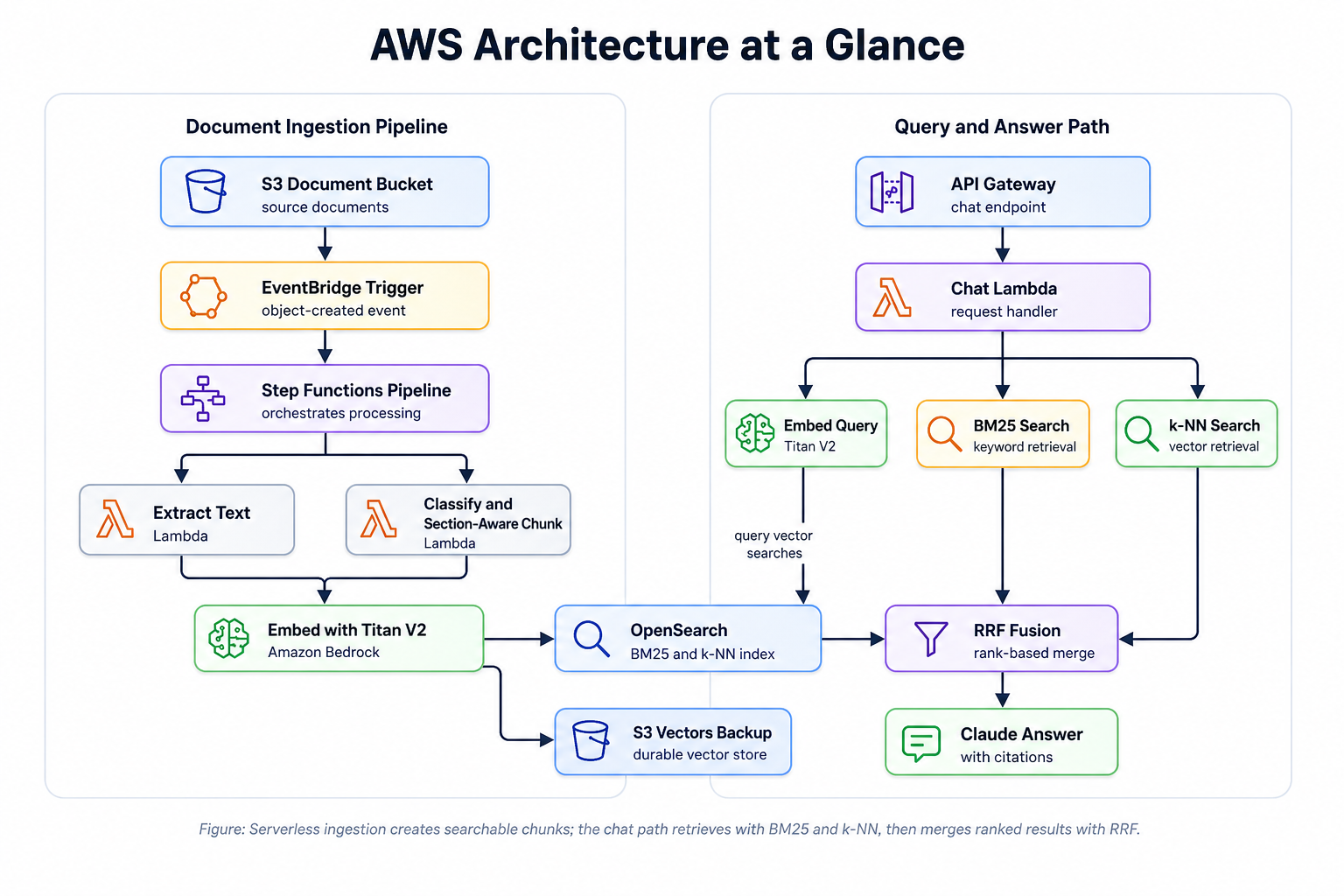
The ingestion pipeline is fully serverless (Lambda, Step Functions, EventBridge). The search layer uses an OpenSearch managed domain — AWS handles patching, backups, and snapshots, but you're provisioning and sizing the cluster (instance types, node counts, storage). This is a deliberate choice: the managed domain gives us UltraWarm tiering for cost-effective warm storage and full control over the k-NN index configuration (HNSW engine, space type, shard count) that OpenSearch Serverless doesn't yet expose.
Key Takeaways
Vector search alone isn't enough for document-heavy RAG. If your queries include broad searches across many documents, you need keyword matching too.
RRF fusion is simple and effective. You don't need a learned ranker or complex score normalization. Rank-based fusion with k=60 works remarkably well.
1024 dimensions is the right choice for Titan V2 when precision matters. The storage savings of 256 or 512 are irrelevant at typical enterprise corpus sizes. The accuracy difference isn't.
Chunk boundaries matter more than chunk size. For structured documents, chunk at section boundaries, not at fixed word counts. The gains are consistent but modest — expect single-digit percentage-point improvements, not a silver bullet.
Hybrid search + section-aware chunking is the combination that unlocks regulatory document search. Either one alone is a partial fix. Together, they handle both the broad keyword queries and the specific semantic queries that compliance teams need.
Try It Yourself
The hybrid search pattern described here works with any OpenSearch cluster that has the k-NN plugin enabled. The key components:
Amazon Bedrock Titan V2 for embeddings (configurable dimensions)
OpenSearch with k-NN plugin (HNSW FAISS) for vector storage + BM25
RRF fusion — ~20 lines of code, no dependencies
def rrf_fusion(result_lists, k=60):
scores = {}
for results in result_lists:
for rank, doc_id in enumerate(results):
scores[doc_id] = scores.get(doc_id, 0) + 1 / (k + rank + 1)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
- Any LLM for the generation step (Claude, GPT-4, Llama, etc.)
If you're building a RAG system for structured documents — regulatory filings, clinical protocols, legal contracts, technical specifications — hybrid search with section-aware chunking is worth the investment. The improvement on broad, recall-heavy queries is often substantial in practice.
Have questions or want to discuss hybrid search architectures? Connect with me on LinkedIn.
The views expressed in this post are my own and do not represent those of my employer.